
Spark cluster execution with Akka
This post follows from the post on Creating composable data pipelines. Wrapping our Spark processes in a reader monad provides a great deal of flexibility, and this includes how we conduct execution of a a Spark program across a cluster. Here we look at how this can be done and take advantage of Akka to coordinate low latency Spark jobs, providing resilience and supervision.
Before we describe how this works, lets backtack a little and talk about the Spark cluster architecture. Spark has a master / slave architecture. To run a Spark job, you effectively send an executable Java (or Python if you are using PySpark) program to the Spark master. This program is called the driver program. The Spark framework parcels off small sequences of operations (typically just functions, anonymous or otherwise that define the map and reduce operations), serializes them, farms them out to the executors. The executors execute these operations in a distributed fashion on the respective partitions of the RDDs.
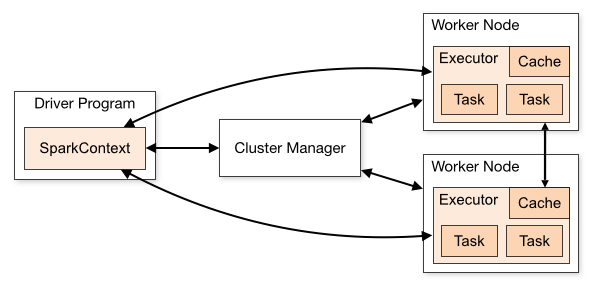
That all works fine, but the part we don’t like that much is the way you submit the driver program to the master node. For a detailed explanation, see the Spark Application Submission Guide, but the short story (in Java / Scala) is as follows: You create an assembly jar (also called an uber jar) with a class with a main method. Then call spark-submit, passing various details, including the jar, and the class with the main method. This jar gets uploaded to the master node, and run there as a Java process.
There are several problems with this:
- We need to monitor an executable process (though Spark does provide a web interface to do this).
- It’s quite a bit of work to get logging information from the driver program back to the client that calls it.
- Each job must run in a separate process; it’s difficult to share resources across these processes.
- The time taken to load the assembly jar with all dependencies rules out the possibility of running short duration, low latency jobs.
- Assembly jars can be a bit of a pain to deal with - they force you to resolve all evictions before the jar will build.
- The process is overall just a bit flaky and brittle.
There are quite a few projects that aim to bridge the gap. These include the Spark Job Server, which provide a REST API to executing Spark, Databricks Cloud has REST APIs that fulfil a similar function. As we at Spring are working with a Scala stack, and are anyway using Akka, we found Akka a great fit for orchestrating the execution of Spark Jobs. The goal was a mechanism for executing spark jobs by calling a simple futures based Scala API, which even abstracted the fact that it was using Akka.
The mechanism works as follows:
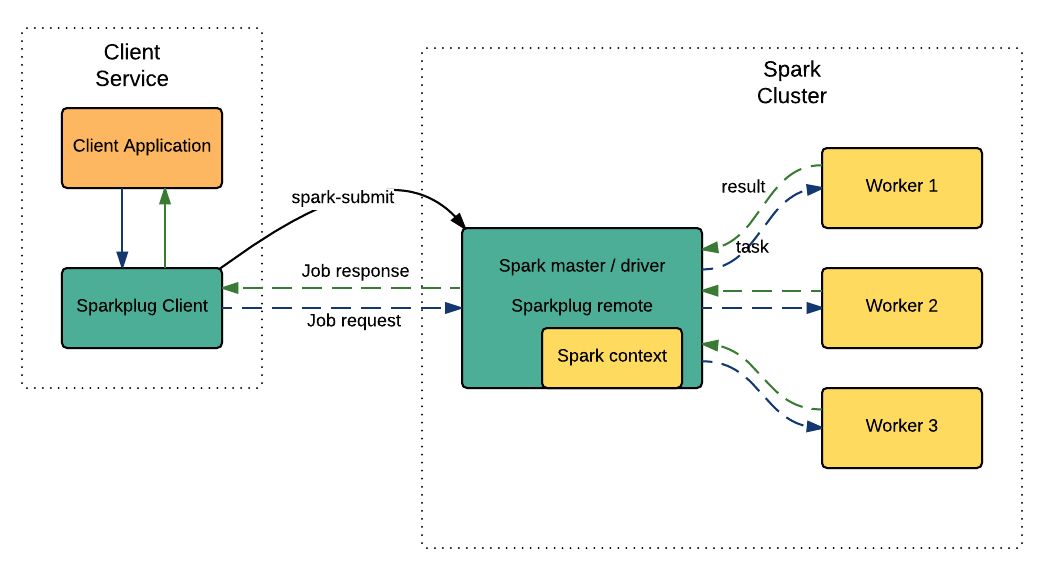
On startup:
- A Spark client service is executed.
- The client service calls
spark-submitto launch the cluster driver program. - As part of this process, all the
jarfiles containing all theSparkOperations are uploaded to the spark master node. This happens on startup, and only has to happen once, not every time a job is submitted. - The driver program instantiates a
SparkContext. This is a long livedSparkContextthat stays up for as long as the driver program is running. - The driver program running on on the master node establishes a remote connection back to the client service.
- The client program is now ready to recieve requests for Spark jobs to be executed.
Per request:
- The client program receives a request to run a Spark job. This could come from anywhere, either in response to a user request, or it could be a scheduled job.
- The client creates an Akka actor, which then sends a message to the remote actor on the master node.
- The request is to create and run a
SparkOperation. TheSparkOperationis instantiated (via a SparkPlugin, described below), and therunmethod is called, using the long-livedSparkContext. When this terminates (successfully or otherwise), a message is sent back to the client (either aJobCompleteorJobFailuremessage, depending on the outcome). - The driver program waits for further requests. In fact, there are no restrictions, many jobs can be run in parallel using the same
SparkContext.
Doing things this way has several advantages:
- More robust error handling - the benefits of actor supervision and death-watches.
- Faster start up times - the minimum latency for a single job goes from seconds to about 30ms.
- More efficient use of resources - a single driver service runs on the master node, rather than multiple executable processes running in their own JVM.
- A user-friendly client interface - a Scala interface rather than a executable with command line parameters.
Creating and executing SparkOperations
As SparkOperations are normally Scala functions, a mechanism is needed to instantiate them. We do this via a SparkPlugin.
import springnz.sparkplug.core
trait SparkPlugin {
// there is a typesafe version of this interface on its way
def apply(input: Option[Any]): SparkOperation[Any]
}
A typical implementation might look like this:
package mypackage
import springnz.sparkplug.core.{ SparkOperation, SparkPlugin }
class MySparkPlugin extends SparkPlugin {
def apply(input: Option[Any]) = mySparkOperation(input)
}
trait ClientExecutor {
def execute[A](pluginClass: String, data: Option[Any]): Future[A]
def shutDown(): Unit
}
Create the ClientExecutor with its companion object.
object ClientExecutor {
def create(params: ClientExecutorParams): ClientExecutor
}
and you might execute the plugin with the following code:
val clientExecutor = clientExecutor.create(executorParams)
...
clientExecutor.execute("mypackage.MySparkPlugin", Some(operationParams))
...
clientExecutor.shutdown()
ClientExecutorParams is a case class that allows you to define configuration separately for the Akka client, the Akka remote, and for the Spark cluster execution.
import com.typesafe.config.Config
case class ClientExecutorParams(
akkaClientConfig: Config = defaultClientAkkaConfig,
sparkConfig: Config = defaultSparkConfig,
akkaRemoteConfig: Option[Config] = None,
jarPath: Option[String] = None)
The configuration of the Sparkplug remote context is entirely dynamically driven from the client end. See the Spark config docs for more information this mechanism. Enough configuration info is provided by default for things to work out the box, but in a serious production environment you would want to take control of this.
All this code is available on Sparkplug, handled in the particular subprojects:
- Client - Sparkplug launcher
- Remote - Sparkplug executor
Execution of Spark jobs on a cluster don’t get a whole lot simpler than this.
How does our monadic abstraction SparkOperation facilitate the cluster execution mechanism? Essentially it gives a common representation in which all our Spark jobs look the same to the execution framework, regardless of the job they are performing. They also look the same as any job that is running locally or within our test framework. This makes them simpler to understand and reason about, as we only need concern ourselves with what they do, rather than the mechanism used to execute them.